

Будущее глубокого обучения можно разбить на эти 3 парадигмы обучения

Будущее глубокого обучения можно разбить на эти 3 парадигмы обучения
Гибридное, композитное и сокращенное обучение
Оригинальный сайт:
Глубокое обучение — это обширная область, сосредоточенная вокруг алгоритма, форма которого определяется миллионами или даже миллиардами переменных и постоянно изменяется — нейронной сети. Кажется, что через день предлагается огромное количество новых методов и приемов.
Однако в целом глубокое обучение в современную эпоху можно разделить на три фундаментальные парадигмы обучения. В каждом лежит подход и вера в обучение, которое предлагает значительный потенциал и интерес к увеличению текущей мощности и масштабов глубокого обучения.
Гибридное обучение — как современные методы глубокого обучения могут преодолеть границы между контролируемым и неконтролируемым обучением, чтобы приспособиться к огромному количеству неиспользуемых немаркированных данных?
Композитное обучение — как различные модели или компоненты могут быть соединены в творческих методах, чтобы создать составную модель, большую, чем сумма ее частей?
Уменьшенное обучение — как можно уменьшить как размер, так и информационный поток моделей как с точки зрения производительности, так и с точки зрения развертывания, сохраняя при этом ту же или большую прогностическую силу?
Будущее глубокого обучения заключается в этих трех парадигмах обучения, каждая из которых тесно взаимосвязана.
Гибридное обучение
Эта парадигма стремится пересечь границы между контролируемым и неконтролируемым обучением. Он часто используется в контексте бизнеса из-за отсутствия и высокой стоимости размеченных данных. По сути, гибридное обучение — это ответ на вопрос,
Как я могу использовать контролируемые методы для решения/в сочетании с неконтролируемыми проблемами?
Во-первых, полууправляемое обучение набирает популярность в сообществе машинного обучения, поскольку оно способно исключительно хорошо работать над контролируемыми задачами с небольшим количеством размеченных данных. Например, хорошо спроектированная полууправляемая GAN (генеративно-состязательная сеть) достигла точности более 90% в наборе данных MNIST после просмотра всего 25 обучающих примеров.
Обучение с полуучителем предназначено для наборов данных, в которых имеется много данных без учителя, но небольшое количество контролируемых данных. В то время как традиционно контролируемая модель обучения будет обучаться на одной части данных, а неконтролируемая модель — на другой, полууправляемая модель может сочетать помеченные данные с выводами, извлеченными из немаркированных данных.
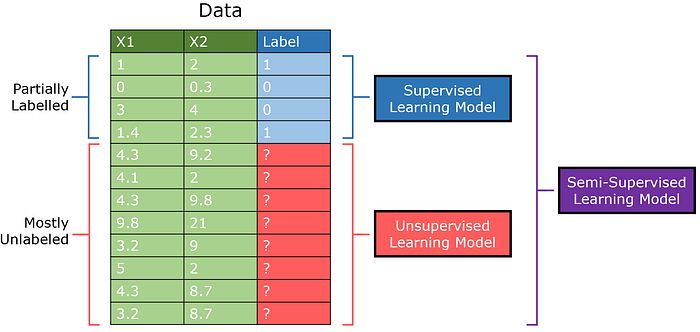
Полууправляемая GAN (сокращенно SGAN) представляет собой адаптацию стандарта Модель генеративно-состязательной сети. Дискриминатор выводит как 0/1, чтобы указать, создано изображение или нет, так и выводит класс элемента (обучение с несколькими выходами).
Это основано на идее, что благодаря обучению дискриминатора различать реальные и сгенерированные изображения он может изучать их структуры без конкретных меток. С дополнительным подкреплением за счет небольшого количества размеченных данных полууправляемые модели могут достигать максимальной производительности с минимальным количеством контролируемых данных.
Вы можете узнать больше о SGAN и полуконтролируемом обучении. здесь.
GAN также участвуют в другой области гибридного обучения — самостоятельный обучение, при котором неконтролируемые задачи явно оформляются как контролируемые. GAN искусственно создают контролируемые данные с помощью генератора; метки создаются для идентификации реальных/сгенерированных изображений. Из неконтролируемой предпосылки была создана контролируемая задача.
В качестве альтернативы рассмотрите возможность использования модели кодер-декодер для сжатия. В своей простейшей форме они представляют собой нейронные сети с небольшим количеством узлов посередине, представляющие своего рода узкое место, сжатую форму. Две секции по обе стороны — это кодер и декодер.
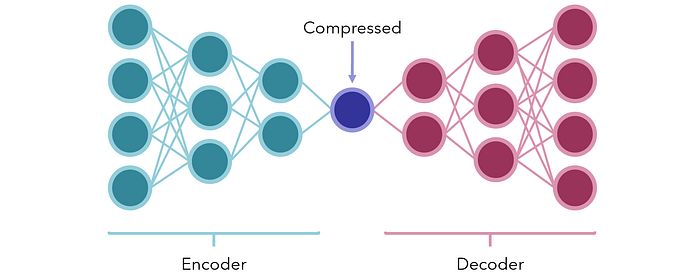
Сеть обучена производить такой же вывод в качестве входного вектора (искусственно созданная контролируемая задача из неконтролируемых данных). Поскольку посередине намеренно расположено узкое место, сеть не может пассивно передавать информацию; вместо этого он должен найти наилучшие способы сохранить содержимое ввода в небольшом блоке, чтобы его можно было снова декодировать декодером.
После обучения кодер и декодер разбираются и могут использоваться на приемных концах сжатых или закодированных данных для передачи информации в чрезвычайно малой форме с минимальными потерями данных или вообще без них. Их также можно использовать для уменьшения размерности данных.
В качестве другого примера рассмотрим большую коллекцию текстов (возможно, комментарии с цифровой платформы). Через некоторую кластеризацию или многообразное обучение метод, мы можем генерировать кластерные метки для коллекций текстов, а затем рассматривать их как метки (при условии, что кластеризация выполнена хорошо).
После интерпретации каждого кластера (например, кластер A представляет комментарии с жалобами на продукт, кластер B представляет положительные отзывы и т. д.) глубокая архитектура НЛП, такая как БЕРТ затем можно использовать для классификации новых текстов в эти кластеры, все с полностью немаркированными данными и минимальным участием человека.
Это еще одно увлекательное приложение для преобразования неконтролируемых задач в контролируемые. В эпоху, когда подавляющее большинство всех данных представляют собой данные без учителя, существует огромная ценность и потенциал в создании творческих мостов для преодоления границ между контролируемым и неконтролируемым обучением с помощью гибридного обучения.
Композитное обучение
Композитное обучение стремится использовать знания не одной модели, а нескольких. Это убеждение в том, что посредством уникальных комбинаций или инъекций информации — как статической, так и динамической — глубокое обучение может постоянно углубляться в понимании и производительности, чем одна модель.
Трансферное обучение является очевидным примером составного обучения и основано на идее, что веса модели могут быть заимствованы из модели, предварительно обученной для аналогичной задачи, а затем настроены для конкретной задачи. Предварительно обученные модели, такие как Зарождение или VGG-16 построены с архитектурой и весами, предназначенными для различения нескольких разных классов изображений.
Если бы мне нужно было обучать нейронную сеть распознаванию животных (кошек, собак и т. д.), я бы не стал обучать сверточную нейронную сеть с нуля, потому что для достижения хороших результатов потребовалось бы слишком много времени. Вместо этого я бы взял предварительно обученную модель, такую как Inception, в которой уже сохранены основы распознавания изображений, и обучил несколько дополнительных эпох в наборе данных.
Точно так же вложения слов в нейронных сетях НЛП, которые сопоставляют слова физически ближе к другим словам в пространстве вложений в зависимости от их отношений (например, «яблоко» и «апельсин» имеют меньшие расстояния, чем «яблоко» и «грузовик»). Предварительно обученные встраивания, такие как GloVe, могут быть помещены в нейронные сети, чтобы начать с того, что уже является эффективным преобразованием слов в числовые, значимые объекты.
Менее очевидно, что конкуренция также может стимулировать рост знаний. Во-первых, генеративно-состязательные сети заимствуют парадигму составного обучения, принципиально противопоставляя две нейронные сети друг другу. Цель генератора — обмануть дискриминатор, а цель дискриминатора — не быть обманутым.
Конкуренцию между моделями будем называть «состязательным обучением», не путать с другим типом состязательного обучения, относящимся к разработка вредоносных входных данных и использование слабых границ решений в моделях.
Состязательное обучение может стимулировать модели, обычно разных типов, в которых производительность модели может быть представлена по отношению к производительности других. Предстоит еще много исследований в области состязательного обучения, при этом генеративно-состязательная сеть является единственным выдающимся творением в этой области.
С другой стороны, конкурентное обучение похоже на состязательное обучение, но выполняется в масштабе от узла к узлу: узлы соревнуются за право реагировать на подмножество входных данных. Конкурентное обучение реализовано в «конкурентном слое», в котором все нейроны одинаковы, за исключением некоторых случайно распределенных весов.
Вектор весов каждого нейрона сравнивается с входным вектором, и активируется нейрон с наибольшим сходством, нейрон «победитель получает все» (выход = 1). Остальные «деактивированы» (выход = 0). Этот неконтролируемый метод является основным компонентом самоорганизующиеся карты и обнаружение признаков.
Другой интересный пример составного обучения находится в поиск нейронной архитектуры. Проще говоря, нейронная сеть (обычно рекуррентная) в среде обучения с подкреплением учится генерировать лучшую нейронную сеть для набора данных — алгоритм находит для вас лучшую архитектуру! Вы можете прочитать больше о теории здесь и реализация на Python здесь.
Методы ансамбля также являются одним из основных продуктов в сложном обучении. Методы глубокого ансамбля доказали свою эффективность. эффективный, а комплексное наложение моделей, таких как кодировщики и декодеры, становится все более популярным.
Большая часть сложного обучения заключается в выяснении уникальных способов построения связей между различными моделями. Он исходит из того, что,
Одна модель, даже очень большая, работает хуже, чем несколько небольших моделей/компонентов, каждая из которых делегирована для выполнения части задачи.
Например, рассмотрим задачу создания чат-бота для ресторана.

Мы можем разделить его на три отдельные части: любезности/болтовня, поиск информации и действие, и разработать модель, специализирующуюся на каждой из них. В качестве альтернативы мы можем делегировать одну модель для выполнения всех трех задач.
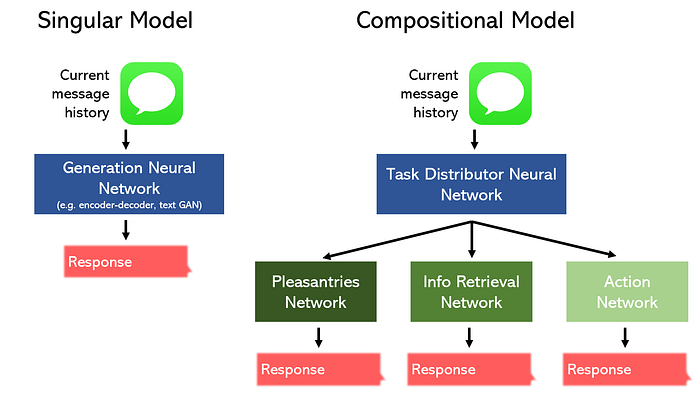
Неудивительно, что композиционная модель может работать лучше, занимая меньше места. Кроме того, такого рода нелинейные топологии можно легко построить с помощью таких инструментов, как Функциональный API Keras.
Для обработки растущего разнообразия типов данных, таких как видео и трехмерные данные, исследователи должны создавать творческие композиционные модели.
Узнайте больше о композиционном обучении и будущем здесь.
Уменьшенное обучение
Размер моделей, особенно в НЛП — эпицентре бурного волнения в исследованиях глубокого обучения — растет. много. Самая последняя модель GPT-3 имеет 175 миллиард параметры. Сравнивая это с БЕРТ это все равно, что сравнивать Юпитер с комаром (ну, не буквально). Будущее глубокого обучения больше?
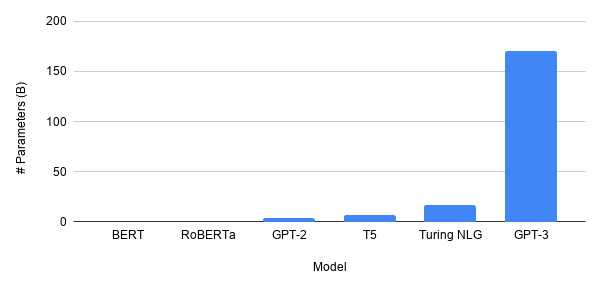
Очень спорно, нет. Общеизвестно, что GPT-3 очень мощная, но в прошлом она неоднократно показывала, что «успешные науки» оказывают наибольшее влияние на человечество. Всякий раз, когда академические круги слишком далеко отходят от реальности, они обычно исчезают во мраке. Так было, когда в конце 1900-х нейронные сети были на короткое время забыты из-за того, что доступных данных было так мало, что идея, какой бы гениальной она ни была, оказалась бесполезной.
GPT-3 — это еще одна языковая модель, и она может писать убедительный текст. Где его приложения? Да, он может генерировать, например, ответы на запрос. Однако есть более эффективные способы сделать это (например, пройти по графу знаний и использовать меньшую модель, такую как BERT, для вывода ответа).
Это просто не похоже на тот случай, когда массивный размер GPT-3, не говоря уже о более крупной модели, осуществим или необходим с учетом высыхание вычислительной мощности.
«Закон Мура как бы выдыхается».
- Сатья Наделла, генеральный директор Microsoft
Вместо этого мы движемся к миру со встроенным ИИ, где умный холодильник может автоматически заказывать продукты, а дроны могут самостоятельно перемещаться по целым городам. Мощные методы машинного обучения должны быть доступны для загрузки на ПК, мобильные телефоны и небольшие микросхемы.
Для этого требуется облегченный ИИ: уменьшение размера нейронных сетей при сохранении производительности.
Оказывается, прямо или косвенно почти все в исследованиях глубокого обучения связано с уменьшением необходимого количества параметров, что идет рука об руку с улучшением обобщения и, следовательно, производительности. Например, введение сверточных слоев резко сократило количество параметров, необходимых нейронным сетям для обработки изображений. Повторяющиеся слои включают идею времени при использовании одних и тех же весов, что позволяет нейронным сетям лучше обрабатывать последовательности и с меньшим количеством параметров.
Слои встраивания явно сопоставляют объекты числовым значениям с физическим значением, так что нагрузка не возлагается на дополнительные параметры. В одной интерпретации, Выбывать слои явно блокируют параметры от работы с определенными частями ввода. L1/L2 регуляризация гарантирует, что сеть использует все свои параметры, убедившись, что ни один из них не становится слишком большим, и каждый из них максимизирует свою информационную ценность.
С созданием специализированных слоев сети требуют все меньше и меньше параметров для более сложных и больших данных. Другие более современные методы явно направлены на сжатие сети.
Обрезка нейронной сети стремится удалить синапсы и нейроны, которые не представляют ценности для выхода сети. Благодаря сокращению сети могут поддерживать свою производительность, удаляя почти все себя.
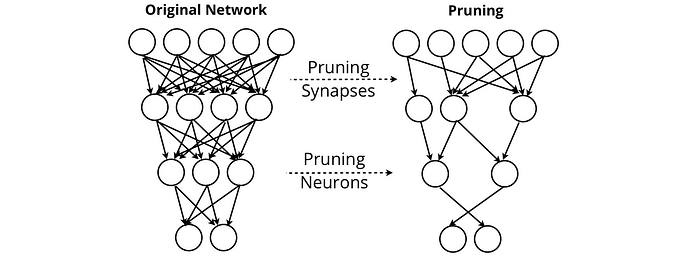
Другие методы, такие как Дистилляция знаний пациентов найти методы сжатия больших языковых моделей в формы, загружаемые, например, на телефоны пользователей. Это было необходимым соображением для Система нейронного машинного перевода Google (GNMT), на котором работает Google Translate, которому нужно было создать высокопроизводительную службу перевода, к которой можно было бы получить доступ в автономном режиме.
По сути, уменьшенное количество центров обучения вокруг дизайна, ориентированного на развертывание. Вот почему большинство исследований по сокращенному обучению проводится исследовательскими отделами компаний. Один из аспектов дизайна, ориентированного на развертывание, заключается не в том, чтобы слепо следовать показателям производительности наборов данных, а в том, чтобы сосредоточиться на потенциальных проблемах при развертывании модели.
Например, упомянутый ранее враждебные входы вредоносные входные данные, предназначенные для обмана сети. Аэрозольная краска или наклейки на знаках могут заставить беспилотные автомобили разогнаться значительно выше установленного ограничения скорости. Часть ответственного сокращенного обучения заключается не только в том, чтобы сделать модели достаточно легкими для использования, но и в том, чтобы они могли учитывать крайние случаи, не представленные в наборах данных.
Сокращенное обучение, возможно, привлекает меньше всего внимания исследований в области глубокого обучения, потому что «нам удалось добиться хорошей производительности с допустимым размером архитектуры» не так привлекательно, как «мы достигаем современной производительности с архитектурой, состоящей из каджиллионов параметров».
Неизбежно, когда раздутая погоня за более высокой долей процента угаснет, как показывает история инноваций, сокращенное обучение — которое на самом деле является просто практическим обучением — получит больше внимания, которого оно заслуживает.
Резюме
Гибридное обучение стремится выйти за рамки контролируемого и неконтролируемого обучения. Такие методы, как частично контролируемое и самоконтролируемое обучение, способны извлекать ценную информацию из неразмеченных данных, что невероятно ценно, поскольку объем данных без учителя растет в геометрической прогрессии.
По мере усложнения задач составное обучение разбивает одну задачу на несколько более простых компонентов. Когда эти компоненты работают вместе — или друг против друга — в результате получается более мощная модель.
Сокращенному обучению не уделяется много внимания, поскольку глубокое обучение переживает фазу ажиотажа, но достаточно скоро появятся практичность и дизайн, ориентированный на развертывание.
Спасибо за чтение!
Заявление: только для академического обмена. Авторские права на эту статью принадлежат оригинальному автору. Если что-то не так, пожалуйста, свяжитесь, чтобы удалить.